The lead researcher behind those Sims-like ‘generative agents’ on the future of AI NPCs

Last week, a couple of us were briefly captivated by the simulated lives of “generative agents” created by researchers from Stanford and Google. Led by PhD student Joon Sung Park (opens in new tab), the research team populated a pixel art world with 25 NPCs whose actions were guided by ChatGPT and an “agent architecture that stores, synthesizes, and applies relevant memories to generate believable behavior.” The result was both mundane and compelling.
One of the agents, Isabella, invited some of the other agents to a Valentine’s Day party, for instance. As word of the party spread, new acquaintances were made, dates were set up, and eventually the invitees arrived at Isabella’s place at the correct time. Not exactly riveting stuff, but all that behavior began as one “user-specified notion” that Isabella wanted to throw a Valentine’s Day party. The activity that emerged happened between the large language model, agent architecture, and an “interactive sandbox environment” inspired by The Sims. Giving Isabella a different notion, like that she wanted to punch everyone in the town, would’ve led to an entirely different sequence of behaviors.
Along with other simulation purposes, the researchers think their model could be used to “underpin non-playable game characters that can navigate complex human relationships in an open world.”
The project reminds me a bit of Maxis’ doomed 2013 SimCity reboot, which promised to simulate a city down to its individual inhabitants with thousands of crude little agents that drove to and from work and hung out at parks. A version of SimCity that used these far more advanced generative agents would be enormously complex, and not possible in a videogame right now in terms of computational cost. But Park doesn’t think it’s far-fetched to imagine a future game operating at that level.
The full paper, titled “Generative Agents: Interactive Simulacra of Human Behavior,” is available here (opens in new tab), and also catalogs flaws of the project—the agents have a habit of embellishing, for example—and ethical concerns.
Below is a conversation I had with Park about the project last week. It has been edited for length and clarity.
PC Gamer: We’re obviously interested in your project as it relates to game design. But what led you to this research—was it games, or something else?
Joon Sung Park: There’s sort of two angles on this. One is that this idea of creating agents that exhibit really believable behavior has been something that our field has dreamed about for a long time, and it’s something that we sort of forgot about, because we realized it’s too difficult, that we didn’t have the right ingredient that would make it work.
Can we create NPC agents that behave in a realistic manner? And that have long-term coherence?
What we recognized when the large language model came out, like GPT-3 a few years back, and now ChatGPT and GPT-4, is that these models that are trained on raw data from the social web, Wikipedia, and basically the internet, have in their training data so much about how we behave, how we talk to each other, and how we do things, that if we poke them at the right angle, we can actually retrieve that information and generate believable behavior. Or basically, they become the sort of fundamental blocks for building these kinds of agents.
So we tried to imagine, ‘What is the most extreme, out there thing that we could possibly do with that idea?’ And our answer came out to be, ‘Can we create NPC agents that behave in a realistic manner? And that have long-term coherence?’ That was the last piece that we definitely wanted in there so that we could actually talk to these agents and they remember each other.
Another angle is that I think my advisor enjoys gaming, and I enjoyed gaming when I was younger—so this was always kind of like our childhood dream to some extent, and we were interested to give it a shot.
I know you set the ball rolling on certain interactions that you wanted to see happen in your simulation—like the party invitations—but did any behaviors emerge that you didn’t foresee?
There’s some subtle things in there that we didn’t foresee. We didn’t expect Maria to ask Klaus out. That was kind of a fun thing to see when it actually happened. We knew that Maria had a crush on Klaus, but there was no guarantee that a lot of these things would actually happen. And basically seeing that happen, the entire thing was sort of unexpected.
In retrospect, even the fact that they decided to have the party. So, we knew that Isabella would be there, but the fact that other agents would not only hear about it, but actually decide to come and plan their day around it—we hoped that something like that might happen, but when it did happen, that sort of surprised us.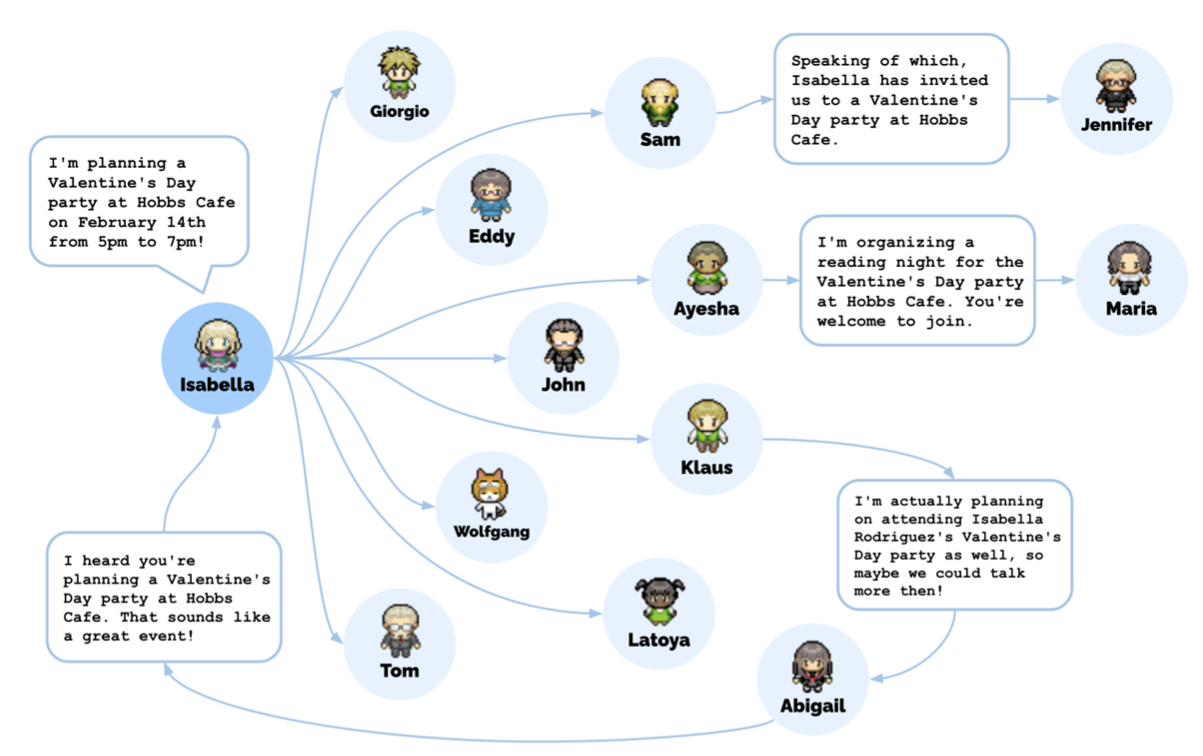
It’s tough to talk about this stuff without using anthropomorphic words, right? We say the bots “made plans” or “understood each other.” How much sense does it make to talk like that?
Right. There’s a careful line that we’re trying to walk here. My background and my team’s background is the academic field. We’re scholars in this field, and we view our role as to be as grounded as we can be. And we’re extremely cautious about anthropomorphizing these agents or any kind of computational agents in general. So when we say these agents “plan” and “reflect,” we mention this more in the sense that a Disney character is planning to attend a party, right? Because we can say “Mickey Mouse is planning a tea party” with a clear understanding that Mickey Mouse is a fictional character, an animated character, and nothing beyond that. And when we say these agents “plan,” we mean it in that sense, and less than there’s actually something deeper going on. So you can basically imagine these caricatures of our lives. That’s what it’s meant to be.
There’s a distinction between the behavior that is coming out of the language model, and then behavior that is coming from something the agent “experienced” in the world they inhabit, right? When the agents talk to each other, they might say “I slept well last night,” but they didn’t. They’re not referring to anything, just mimicking what a person might say in that situation. So it seems like the ideal goal is that these agents are able to reference things that “actually” happened to them in the game world. You’ve used the word “coherence.”
That’s exactly right. The main challenge for an interactive agent, the main scientific contribution that we’re making with this, is this idea. The main challenge that we are trying to overcome is that these agents perceive an incredible amount in their experience of the game world. So if you open up any of the state details and see all the things they observe, and all the things they “think about,” it’s a lot. If you were to feed everything to a large language model, even today with GPT-4 with a really large context window, you can’t even fit in half a day in that context window. And with ChatGPT, not even, I’d say, an hour worth of content.
So, you need to be extremely cautious about what you feed into your language model. You need to bring down the context into the key highlights that are going to inform the agent in the moment the best. And then use that to feed into a large language model. So that’s the main contribution we’re trying to make with this work.
What kind of context data are the agents perceiving in the game world? More than their location and conversation with other NPCs? I’m surprised by the volume of data you’re talking about here.
So, the perception these agents have is designed quite simply: it’s basically their vision. So they can perceive everything within a certain radius, and each agent, including themselves, so they make a lot of self-observation as well. So, let’s say if there’s a Joon Park agent, then I’d be not only observing Tyler on the other side of the screen, but I’d also be observing Joon Park talking to Tyler. So there’s a lot of self-observation, observation of other agents, and the space also has states the agent observes.
A lot of the states are actually quite simple. So let’s say there’s a cup. The cup is on the table. These agents will just say, ‘Oh, the cup is just idle.’ That’s the term that we use to mean ‘it’s doing nothing.’ But all of those states will go into their memories. And there’s a lot of things in the environment, it’s quite a rich environment that these agents have. So all that goes into their memory.
So imagine if you or I were generative agents right now. I don’t need to remember what I ate last Tuesday for breakfast. That’s likely irrelevant to this conversation. But what might be relevant is the paper I wrote on generative agents. So that needs to get retrieved. So that’s the key function of generative agents: Of all this information that they have, what’s the most relevant one? And how can they talk about that?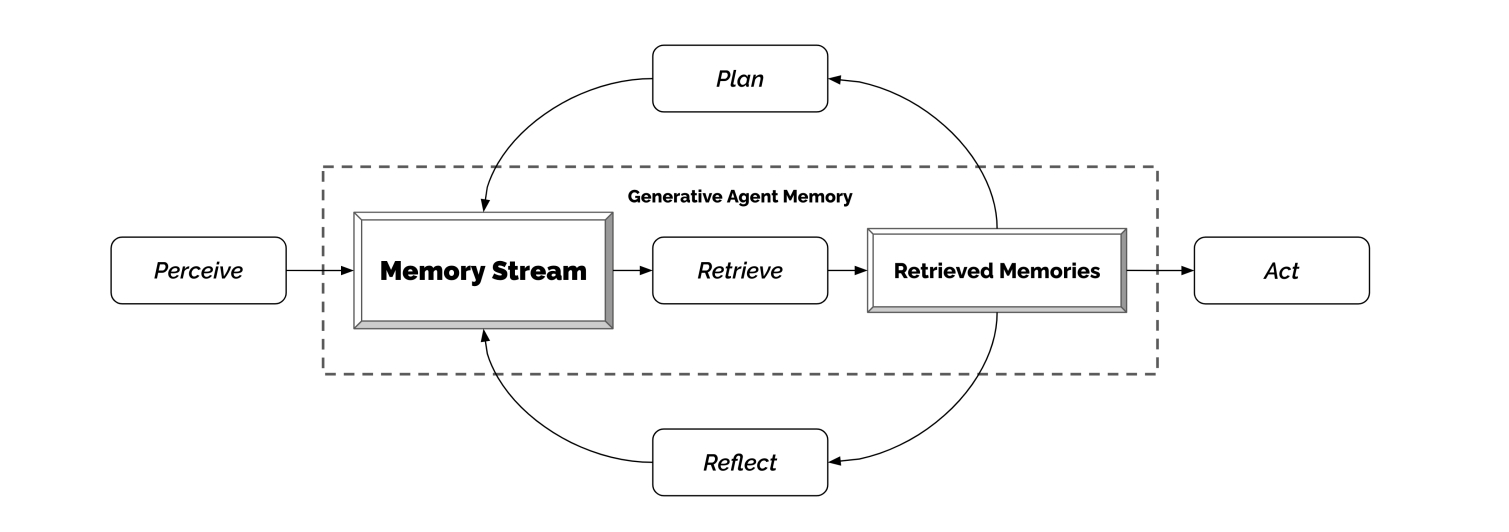
Regarding the idea that these could be future videogame NPCs, would you say that any of them behaved with a distinct personality? Or did they all sort of speak and act in roughly the same way?
There’s sort of two answers to this. They were designed to be very distinct characters. And each of them had different experiences in this world, because they talked to different people. If you are with a family, the people you likely talk to most is your family. And that’s what you see in these agents, and that influenced their future behavior.
Do we want to create models that can generate bad content, toxic content, for believable simulation?
So, they start with distinct identities. We give them some personality description, as well as their occupation and existing relationship at the start. And that input that basically bootstraps their memory, and influences their future behavior. And their future behavior influences more future behavior. So these agents, what they remember and what they experience is highly distinct, and they make decisions based on what they experience. So they end up behaving very differently.
I guess at the simplest level: if you’re a teacher, you go to school, if you’re a pharmacy clerk, you go to the pharmacy. But it also is the way you talk to each other, what you talk about, all those changes based on how these agents are defined and what they experience.
Now, there are the boundary cases or sort of limitations with our current approach, which uses ChatGPT. ChatGPT was fine tuned on human preferences. And OpenAI has done a lot of hard work to make these agents be prosocial, and not toxic. And in part, that’s because ChatGPT and generative agents have a different goal. ChatGPT is trying to become really a useful tool that is for people that minimizes the risk as much as possible. So they’re actively trying to make this model not do certain things. Whereas if you’re trying to create this idea of believability, humans do have conflict, and we have arguments, and those are a part of our believable experience. So you would want those in there. And that is less represented in generative agents today, because we are using the underlying model, ChatGPT. So a lot of these agents come out to be very polite, very collaborative, which in some cases is believable, but it can go a little bit too far.
Do you anticipate a future where we have bots trained on all kinds of different language sets? Ignoring for now the problem of collecting training data or licensing it, would you imagine, say, a model based on soap opera dialogue, or other things with more conflict?
There’s a bit of a policy angle to this, and sort of what we, as a society and community decide is the right thing to do here is. From the technical angle, yes, I think we’ll have the ability to train these models more quickly. And we already are seeing people or smaller groups other than OpenAI, being able to replicate these large models to a surprising degree. So we will have I think, to some extent, that ability.
Now, will we actually do that or decide as a society that it’s a good idea or not? I think it’s a bit of an open question. Ultimately, as academics—and I think this is not just for this project, but any kind of scientific contribution that we make—the higher the impact, the more we care about its points of failures and risks. And our general philosophy here is identify those risks, be very clear about them, and propose structure and principles that can help us mitigate those risks.
I think that’s a conversation that we need to start having with a lot of these models. And we’re already having those conversations, but where they’ll land, I think it’s a bit of an open question. Do we want to create models that can generate bad content, toxic content, for believable simulation? In some cases, the benefit may outweigh the potential harms. In some cases, it may not. And that’s a conversation that I’m certainly engaged with right now with my colleagues, but also it’s not necessarily a conversation that any one researcher should be deciding on.
One of your ethical considerations at the end of the paper was the question of what to do about people developing parasocial relationships with chatbots, and we’ve actually already reported on an instance of that. In some cases it feels like our main reference point for this is already science fiction. Are things moving faster than you would have anticipated?
Things are changing very quickly, even for those in the field. I think that part is totally true. We’re hopeful that a lot of the really important ethical discussions we can have, and at least start to have some rough principles around how to deal with these concerns. But no, it is moving fast.
It is interesting that we ultimately decided to refer back to science fiction movies to really talk about some of these ethical concerns. There was an interesting moment, and maybe this does illustrate this point a little bit: we felt strongly that we needed an ethical portion in the paper, like what are the risks and whatnot, but as we were thinking about that, but the concerns that we first saw was just not something that we really talked about in academic community at that point. So there wasn’t any literature per se that we could refer back to. So that’s when we decided, you know, we might just have to look at science fiction and see what they do. That’s where those kinds of things got referred to.
And I think I think you’re right. I think that we are getting to that point fast enough that we are now relying to some extent on the creativity of these fiction writers. In the field of human computer interaction, there is actually what’s called a “generative fiction.” So there are actually people working on fiction for the purpose of foreseeing potential dangers. So it’s something that we respect. We are moving fast. And we are very much eager to think deeply about these questions.
You mentioned the next five to 10 years there. People have been working on machine learning for a while now, but again, from the lay perspective at least, it seems like we’re suddenly being confronted with a burst of advancement. Is this going to slow down, or is it a rocket ship?
What I think is interesting about the current era is, even those who are heavily involved in the development of these pieces of technology are not so clear on what the answer to your question is. So, I’m saying that’s actually quite interesting. Because if you look back, let’s say, 40 or 50 years, or we’re when we’re building transistors for the first few decades, or even today, we actually have a very clear eye on how fast things will progress. We have Moore’s Law, or we have a certain understanding that, at every instance, this is how fast things will advance.
I think in the paper, we mentioned a number of like a million agents. I think we can get there.
What is unique about what we are seeing today, I think, is that a lot of the behaviors or capacities of AI systems are emergent, which is to say, when we first started building them, we just didn’t think that these models or systems would do that, but we later find that they are able to do so. And that is making it a little bit more difficult, even for the scientific community, to really have a clear prediction on what the next five years is going to look like. So my honest answer is, I’m not sure.
Now, there are certain things that we can say. And that often is within the scope of what I would say are optimization and performance. So, running 25 agents today took a fair amount of resources and time. It’s not a particularly cheap simulation to run even at that scale. What I can say is, I think within a year, there are going to be some, perhaps games or applications, that are inspired by candidate agents. In two to three years, there might be some applications that make a serious attempt at creating something like generative agents in a more commercial sense. I think in five to ten years, it’s going to be much easier to create those kinds of applications. Whereas today, on day one, even within a scope of one or two years, I think it’s going to be a stretch to get there.
Now, in the next 30 years, I think it might be possible that computation will be cheap enough that we can create an agent society with more than 25 agents. I think in the paper, we mentioned a number of like a million agents. I think we can get there, and I think those predictions are slightly easier for a computer scientist to make, because it has more to do with the computational power. So those are the things that I think I can say for now. But in terms of what AI will do? Hard to say.


